정올 문제들이 전반적으로 괜찮다고 생각한다.
적당히 높은 수준, 참신한 아이디어 등등.. 그래서 골드 문제들만 찍먹하기로 했다.
백준 17623 괄호 ( 2019 고등부 본선 2번 )
17623번: 괄호
6개의 문자 ‘(’, ‘)’, ‘{’, ‘}’, ‘[’, ‘]’ 로 이루어진 올바른 괄호 문자열 W에 대하여 정수의 ‘괄호값’을 지정하는 함수 val(W)가 정의되어 있다. 먼저 올바른 괄호 문자열부터 정의해
www.acmicpc.net
되게 참신한 문제다. 나만 몰랐던 건가?
풀이>>
주요 아이디어: DP
문제에서는 마치 변수 두 개를 만족하는 최적해를 내놓으라는 것 같아서 접근이 힘들어 보이는데, 잘 보면 괄호 값 자체는 고정되어 있다. 그러면 우리는 DP식을 다음과 같이 세울 수 있다:
$DP[n]:$ 괄호의 값이 $n$이면서, $dmap$ 값이 최소인 괄호 문자열
즉, DP의 값 자체가 괄호가 되는 것이다! DP에 실수가 들어가는 건 봤어도 문자열이 들어가는 건 처음 본다.
이제 점화식을 건설해 보자. 문제에 나와 있듯이, 그 다음 괄호열을 만들기 위해서는 이전 괄호열에 괄호를 씌우거나, 다른 괄호열을 갖다 붙여줘야 한다.
따라서..
$DP[n]\,=\,\begin{cases} \,\, [ \, + \, DP[n/5 ] \, + \, ] \\ \,\, \{ \, + \, DP[n/3] \, + \, \} \\ \,\, ( \, + \, DP[n/2] \, + \, ) \\ \,\, \underset{1<x<n}{min}(DP[x]+DP[n-x]) \end{cases}$
중 최솟값이 된다. 나눗셈은 배수일 때만 하자.
빡센 문자열 연산이 동반되기 때문에, 정신건강을 위해 std::string을 활용하자.
백준 10840 구간 성분 ( 2015 고등부 본선 2번 )
10840번: 구간 성분
첫 두 줄에 신호 서열이 공백 없는 하나의 문자열로 각각 주어진다. 이 문자열은 영문 소문자로만 구성되어 있다. 두 입력 문자열의 크기 N, M의 범위는 1 ≤ N, M ≤ 1,500 이다.
www.acmicpc.net
옛날이었다면 절대 못 풀었을 것 같다. 잡기술만 늘어난 기분 ㅋㅋ
풀이>>
주요 아이디어: 해싱, 이분 탐색, 모듈러 역원, DP
혹자는 해싱으로 모든 문자열 문제를 풀 수 있다고도 한다. 이 문제의 정해가 뭔지는 모르겠지만 믿음의 해싱이 굉장히 잘 먹힌다.
0. Naive하게 풀기
$O(N)$개의 가능한 문자열 길이에 대해서, 모든 부분 문자열 $O(N)$, $O(M)$개씩을 잡고, $O(N)$개의 문자들을 비교하면 된다. 그러면 대략적으로 $O(N^4)$에 풀린다. 당연히 이렇게 풀면 안 된다. 천천히 차수를 내릴 건데, 일단 문자열을 비교하는 과정을 개선하는 것부터 시작하자. 이는 해싱을 이용하면 쉽게 할 수 있다.
1. 어떻게 해싱을 할 것인가?
특정 문자 집합을 대표할 수 있어야 한다. 막 섞어도 값이 같은 곱셈을 활용하자. (덧셈도 좋지만, 곱셈을 써야 안 겹칠 확률이 높다)
소수 체를 200쯤까지 돌린다. 그 뒤에 모든 알파벳을 순서대로 소수와 대응시킨다. 그리고 적당히 큰 소수 $P$를 잡자.
이제 어떤 문자열 $S\,=\,a_1a_2...a_n$ 의 해시 $f(S)$를 $f(S) = \prod_{i=1}^n {p}_{a_i} (mod\,P)$로 정의하면 보통은 '구간 성분' 이 같은 문자열들끼리만 해시값이 같게 된다.
만약 운 나쁘게 저격당하게 된다면 $P$의 값을 바꾸는 방법으로 해결할 수 있다. 아예 해시가 겹칠 확률이 너무 높은 것이 문제라면, $P$를 여러 개 잡아서 해시값을 여러 개 만들면 된다.
2. 빠르게 해싱하기
그러면 된 건가? 아까와 마찬가지로, $O(N)$개의 가능한 문자열 길이에 대해서, 모든 부분 문자열 $O(N+M)$개에 $O(N)$만에 해싱하고, $O(NM)$번 비교하게 될 테니 대락적 시간복잡도는 $O(N^3)$이다. 더 줄일 필요성이 있다.
이번에는 해싱을 빠르게 해 보자. 중요한 점은 인접한 부분 문자열들은 크게 변하지 않는다는 것이다.
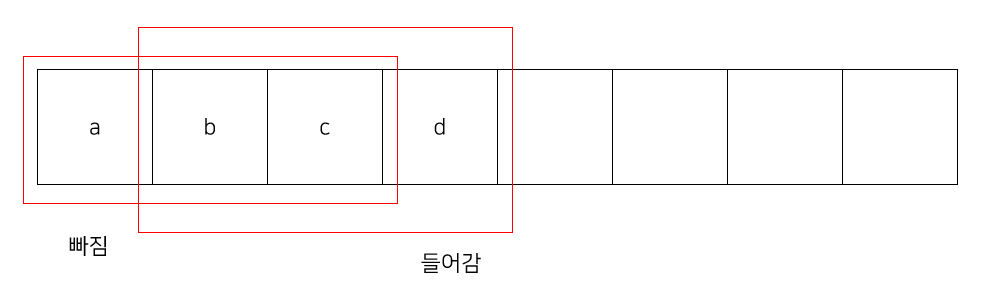
예를 들자면 이런 식이다. 길이 3짜리 부분 문자열들을 추출하면, 위 사진에서 보이다시피 그 다음 부분 문자열은 이전의 것에서 크게 변하지 않는다. 그 다음 문자가 들어가고, 맨 앞에 있던 문자는 빠진다.
그러면, 이전 해시값을 알 때 다음 해시값은 DP 느낌으로 $O(1)$에 알 수 있다. 빠지는 문자를 나누고, 들어가는 문자를 곱하면 된다.
다만 여기서 한 가지 문제점이 있는데, 모듈러에서 나누기를 쉽게 할 수 없다는 것이다. 이럴 때 사용하는 것이 모듈러 역원이다. 어떤 수로 나눗셈을 하는 대신에, 그 수의 역원을 곱하면 나눗셈이 해결된다. 이를 구하는 복잡한 알고리즘들이 있지만, 우리가 애초에 $P$를 소수로 잡았기 때문에 역원은 $a^{P-2}$꼴이 된다. 이는 페르마의 소정리를 통해 알 수 있다.
따라서, 역원 전처리를 하고 나면 DP를 통해 모든 해시값들을 $O(N^2)$가 아닌 $O(N)$에 알 수 있게 되었다!
3. 빠르게 비교하기
하지만, 아직도 끝나지 않았다. 우리가 비교를 $O(NM)$에 해 주고 있기 때문이다. 그러면 여전히 총 시간복잡도는 $O(N^3)$이 된다. 이를 해결하기 위해, 한 해시값을 미리 정렬해둔 뒤 lower_bound로 다른 해시값들과 같은 것이 있는지 찾아 주면 비교를 $O(NlogN)$에 수행할 수 있다.
그러면 문제는 길이 $O(N)$에, 검사하는 비용 $O(NlogN)$을 곱해서 $O(N^2 logN)$에 풀리며, 아주 널널하게 통과한다.
백준 2169 로봇 조종하기 ( 2002 고등부 본선 1번 )
2169번: 로봇 조종하기
첫째 줄에 N, M(1≤N, M≤1,000)이 주어진다. 다음 N개의 줄에는 M개의 수로 배열이 주어진다. 배열의 각 수는 절댓값이 100을 넘지 않는 정수이다. 이 값은 그 지역의 가치를 나타낸다.
www.acmicpc.net
5분컷..
풀이>>
주요 아이디어: DP
$DP[x][y][bf]$를 다음과 같이 정의하자: $bf$방향으로 이동해 $(x, \, y)$좌표에 도착했을 때 얻을 수 있는 최대 점수
그러면 위쪽에서 이동해온 경우에는 아무렇게나 가면 되고, 왼쪽, 오른쪽에서 이동해온 경우에는 원래 좌표로 돌아가지 않으면 되기 때문에 DP식이 금방 나온다.
백준 20191 줄임말 ( 2020 고등부 본선 1번 )
20191번: 줄임말
문자열 A가 문자열 B의 줄임말이라는 것은 B의 순서를 바꾸지 않고 0 또는 그 이상 개수의 문자를 지워 A를 만들 수 있다는 뜻이다. 정의에 의해서 B는 자기 자신의 줄임말임에 유의하라. 예를 들
www.acmicpc.net
수많은 KOI 참가자들이 10분컷 냈다는 문제.
나는 절대 못 할 것 같다.
풀이>>
주요 아이디어: 이분 탐색, 시뮬레이션
문자열을 붙인다고 생각하지 말고, $T$를 빙빙 돌고 있다고 생각하자. 빙빙 돌면서 $S$에서 요구하는 문자들을 순서대로 계속 찾을 것이다. 돌아간 횟수가 답이다. 그런데, 그냥 막 돌면 $O(NM)$이라서 시간 초과가 난다. 여기서 생각하는 것이 이분 탐색이다.
$S$에서 이번에 찾아야 하는 문자가 'a'라고 하자. 또, 지금 T의 $i$번째 문자까지 돈 상태라고 하자.
$T$에서 'a'가 나타나는 위치들을 정렬된 상태로 전부 저장해 놓자. 그리고 그 위치들에서 $i$보다 큰 첫 위치 $idx$를 찾는다. 이 과정을 이분 탐색으로 해결하면 된다.
그러면, $idx$가 곧 내가 빙빙 돌면서 처음으로 찾게 될 'a'의 위치이다. $i$를 $idx$로 바꾸고 S의 다음 문자를 찾는다.
만약 그런 $idx$가 존재하지 않는다면 돌아간 횟수를 1 증가시키고 $i$를 처음으로 'a'가 등장한 인덱스로 바꾸면 된다.
시간복잡도는 $O(NlogM)$이 된다.
백준 17612 쇼핑몰 ( 2019 고등부 예선 1번 )
17612번: 쇼핑몰
입력의 첫 줄에는 2개의 정수 N(1 ≤ N ≤ 100,000)과 k(1 ≤ k ≤ 100,000)가 주어진다. 다음 줄부터 N개의 줄에 걸쳐 고객 N명의 정보가 줄 맨 앞의 고객부터 맨 뒤 고객까지 순서대로 주어진다. i번째
www.acmicpc.net
본인이 대회 당시 당당히 0점을 맞은 문제이다. ㄷㄷ처음 풀이를 들었을 때는 이해가 안 갔는데 천천히 곱씹으니까 대강 풀이가 이해가 갔다. 다만 구현법이 저게 맞는지는 모르겠다..
풀이>>
주요 아이디어: 우선 순위 큐, 덱(Not essential)
덱을 쓰는 풀이는 진짜 나밖에 없는 거 같은데, 강력한 뇌절의 결과물이다.
이 문제에서 주목할 부분은, 줄을 세우는 것과 계산해서 나가는 문제가 아예 독립이라는 것이다.
1. 줄 세우기
우리는 계산대를 우선 순위 큐에 넣을 것이다. 계산대에서 계산하는 총 물건의 양에 따라서 우선 순위 큐가 정렬하도록 한다.
그러면 항상 손님이 들어갈 위치가 우선 순위 큐의 맨 앞에 온다. 그 계산대에 손님을 넣은 뒤에 다시 우선 순위 큐로 대입해주면 된다. 시간복잡도는 $O(NlogN)$ 이다.
2. 계산해서 나가기
계산대마다 사람들이 들어 있을 것이다. 이제 뒤쪽 계산대부터 본다.
w가 20보다 작기 때문에 그냥 1씩 빼면서 마구 시뮬레이션 해도 시간이 안 부족하다.
반복문을 계속 돌리면서 각 계산대마다 물건을 하나씩 계산한다. 그러다가 물건이 0개가 되는 사람이 있으면 다음으로 넘어간다. 이걸 반복하면서 사람이 0명이 되면 끝내면 된다.
여기서 그냥 계산대에서 계산하고 있는 사람들의 인덱스들을 잘 관리하면 해결되는데, 다 계산한 사람은 삭제해야 한다는 강박관념에 휩싸여서 덱을 써 버렸다;; 계산대에 들어간 사람들을 덱을 이용해서 동적으로 관리한다는 느낌. 물건을 하나씩 계산할 때는 앞에서 빼서 다시 앞으로 넣어야 하고, 처음 계산대에 사람들을 넣을 때에는 뒤로 넣어야 해서 덱을 썼다.
따라서 총 시간복잡도는 $O(NlogN)$이다.
예상한 대로 재밌다. 정보 좀 잘해보자~
'PS' 카테고리의 다른 글
| 2021 NYPC 연습문제 풀기 (0) | 2021.08.18 |
|---|---|
| 8월 1주차 PS (0) | 2021.08.03 |
| 2월 4주차 PS: 문자열 (0) | 2021.02.26 |
| 2.18 PS: 도전 (0) | 2021.02.18 |
| 2.17 PS: 세종정보올림피아드 밀기 (0) | 2021.02.18 |
